1. Outline
The KIT Speaking Test Corpus is developed by Katsunori Kanzawa at the Kyoto Institute of Technology (KIT) and his team. The corpus contains transcribed speech responses to the KIT Speaking Test, a computer-based English speaking test administered to all first-year undergraduates at KIT.
The corpus is free for everyone. There are two ways to use it: by downloading it or using it on Jupyter Notebook. Please refer to Section 5 for downloading and Section 6 for using it on Jupyter Notebook. Please read the terms and conditions in Section 9 before using the corpus.
This project has been approved by the KIT Research Ethics Review Board. Only the speech responses from examinees who have agreed to the project are used for the corpus.
2. Background
English education in Japan tends to focus on communication. To provide evidence-based English education in this context, it is essential to know the current status of the speaking ability of English learners whose native language is Japanese and the characteristics of their development process.
KIT has developed its own English speaking test and has been administering it regularly to all first-year undergraduates. This project creates a corpus of students’ speech responses to the test, which can be analysed to reveal characteristics of the speaking ability of English learners whose native language is Japanese. We believe that the results can significantly contribute to the field of English education and test development and can be applied to other areas we have not yet imagined.
3. Key features
(1) The corpus contains data from almost all the first-year undergraduates at one Japanese university.
Generally, such learner corpus development tends to see participation from people with relatively high proficiency and/or interest in the language, resulting in a sample that tends to deviate from the target population. As this corpus is based on the KIT Speaking Test administered to all first-year undergraduates at KIT, its data is much closer to reality. Analyzing this corpus would allow us to answer questions such as “What is the level of Japanese university students’ speaking proficiency?” or “What can they do and what can’t they do?”
(2) The corpus is tagged.
The corpus contains not only transcriptions of speech responses, but also tags to indicate speech characteristics. Analyzing the utterances using these tags as clues would allow us to answer questions such as “What are the areas in which examinees struggle?” or “What communication strategies do they use to tackle difficulties?”
(3) Attribute data and test scores of each examinee are attached to the corpus.
The corpus contains the attribute data and the KIT Speaking Test and TOEIC scores of each examinee. Analyzing the relationship between attribute data and speech allows us to answer questions such as “Are there attributes or backgrounds that affect students’ performance?”
Furthermore, analyzing the relationship between test scores and speech can help us explore questions such as “What language features contribute significantly to test scores?” or “Are other skills (listening and/or reading) related to speaking ability?”
Additionally, test scores can predict the approximate proficiency level of the students. Thus, we could investigate questions such as “How do students perform differently at different levels of proficiency?” or “How does their performance change when their proficiency level goes up?”
(4) The corpus is compatible with the NICT JLE Corpus.
The file format and transcription/tagging methods of this corpus conform to those of the NICT JLE Corpus. This allows us to compare data with the NICT JLE Corpus and answer questions such as “How consistent are the analysis results across corpora?” or “Are there similarities or differences between corpora? What causes them, if any?”
(5) Test items (questions) are open to the public.
The test items of the KIT Speaking Test, on which this corpus is based, are also available on this website. Analyzing the corpus in relation to the test items would allow us to answer questions such as “How do test items affect examinees’ performance?” or “What tasks are effective in eliciting examinees’ performance?”
(6) Transcribed data by an automated transcription tool (Video Indexer) is available.
To build the corpus, we first used Video Indexer (currently Video Analyzer for Media), an automated transcription tool by Microsoft, to automatically transcribe the speech responses. Then, we conducted a manual revision of the text. The Video Indexer data are published on this website along with the final transcribed data. A comparison of these data could address “How accurate are automated transcription tools at this point in time?” Moreover, since this type of speech recognition technology is used for automated scoring, it might help answer “To what extent is automated scoring of speaking tests possible at this point in time?”
4. About the corpus
4.1 Target data
The corpus is based on speech responses to the KIT Speaking Test administered to all first-year graduates of KIT.
The KIT Speaking Test is a computer-based English speaking test in which questions are presented using audio and PC display, and the examinees’ responses are recorded through their headset microphone.
One of the three versions of the test was administered to each student. We have tentatively named the tests Ver. 1, 2, and 3.
The KIT Speaking Test consists of three parts with nine questions in total. A summary of each part is as follows:
- Part 1: Examinees respond based on the pictures presented (no planning time).
- Part 2: Examinees listen to a conversation. They then summarize it and express their own opinions about it (no planning time).
- Part 3: Examinees organize their thoughts and opinions under a planning time of 60 sec and discuss them logically.
The following table shows the list of test items of Ver. 1 to Ver. 3. The full version of the items can be downloaded from 5.1.
| Question NO. | Task type | Response time(sec.) | Ver. 1 | Ver. 2 | Ver. 3 | |
|---|---|---|---|---|---|---|
| Part 1 | Q1 | Imagine | 45 | Imagine why the bicycle is left here | Imagine why the cup is left here. | Imagine why the bags are left here. |
| Q2 | Imagine | 45 | Imagine what the man is thinking. | Imagine what the man is thinking. | Imagine what the boy is thinking. | |
| Q3 | Compare | 45 | Which of these things would you buy for a 5-year-old child to play with, building blocks or a computer? Explain the reasons for your choice, comparing the advantages and disadvantages of both. | Which of these places would you prefer to live in, a large house or a high-rise apartment? Explain the reasons for your choice, comparing the advantages and disadvantages of both. | Where would you take your guests from abroad, to the countryside or to a big city? Explain the reasons for your choice, comparing the advantages and disadvantages of both. | |
| Part 2 | Q4 | Identify different values | 45 | How are Bill’s and Kyoko’s opinions different? | How are Bill’s and Mariam’s opinions different? | How are Kenji’s and Susan’s opinions different? |
| Q5 | Take position | 60 | Which way of thinking do you support? Explain your position and give reasons. | Which way of thinking do you support? Explain your position and give reasons. | Which way of thinking do you support? Explain your position and give reasons. | |
| Q6 | Identify problem | 45 | What is the problem Kate is facing? | What is the problem Susan is facing? | What is the problem Mariam is facing? | |
| Q7 | Problem solving | 60 | If you were Kate, what would you do to solve the problem? | If you were Susan, what would you do to solve the problem? | If you were Mariam, what would you do to solve the problem? | |
| Part 3 | Q8 | Plan and organise | 60 | You have been asked to make a promotional video of your university. Explain how you would organize it. | You want to establish a new cycling club in your university. Explain how you would organize it. | You want to organize a party for your high school classmates. Explain how you would organize it. |
| Q9 | Persuade | 60 | You are talking with friends from other countries about holidays. Explain to them why they should visit your country. | Some friends from another country are visiting you for one week. Choose a place for them to go and explain why they should go there. | You are talking with friends about hobbies. Explain to them why your hobby is interesting and why they should try it. |
Examinees’ responses are evaluated based on two criteria: Task Achievement and Task Delivery. The rating scales are as follows:
| Score | Task Achievement (80% weighting) | Task Delivery (20% weighting) |
|---|---|---|
| 5 | The task is achieved, being developed with a satisfactory level of detail. | The delivery is mostly confident. Given time is well used without obvious problems with delivery such as intrusive pauses, hesitations, or repetitions. |
| 4 | The task is mostly achieved, with some supporting detail in places. | Given time is quite well used despite some problems with delivery such as slow rate of speech, pauses, hesitations, or repetitions. |
| 3 | The task is minimally or partially achieved, being supported with some basic detail. | General meaning comes across, but given time is not effectively used because of problems with delivery such as slow rate of speech, pauses, hesitations, or repetitions. |
| 2 | The task is addressed, but there is no or very little supporting detail. | The speaker keeps trying, but problems with delivery (e.g. slow rate of speech, pauses, hesitations or repetitions) allow a very limited amount of meaning to be conveyed. |
| 1 | The task remains essentially unachieved, though there may be some relevant words. | The speaker gives up trying, or problems with delivery (e.g. slow rate of speech, pauses, hesitations, repetitions) are fatal to meaning coming across. |
| 0 | There is no relevant contribution (e.g. content is entirely unconnected to topic). | The speaker does not start the task (e.g. s/he is silent, utters only fillers, or just says, ‘I don’t know’). |
After the rating, Task Achievement is weighted at 80% and Task Delivery at 20%. The score is calculated on a 100-point scale. Scores are equated using Item Response Theory (IRT) so that they can be compared across versions.
The scores of the KIT Speaking Test and those of TOEIC are attached to the corpus. The summary of the scores is as follows:
KIT Speaking Test (0–100): Average – 48.0, Highest – 90, Lowest – 21
TOEIC (10–990): Average – 563.6, Highest – 985, Lowest – 195
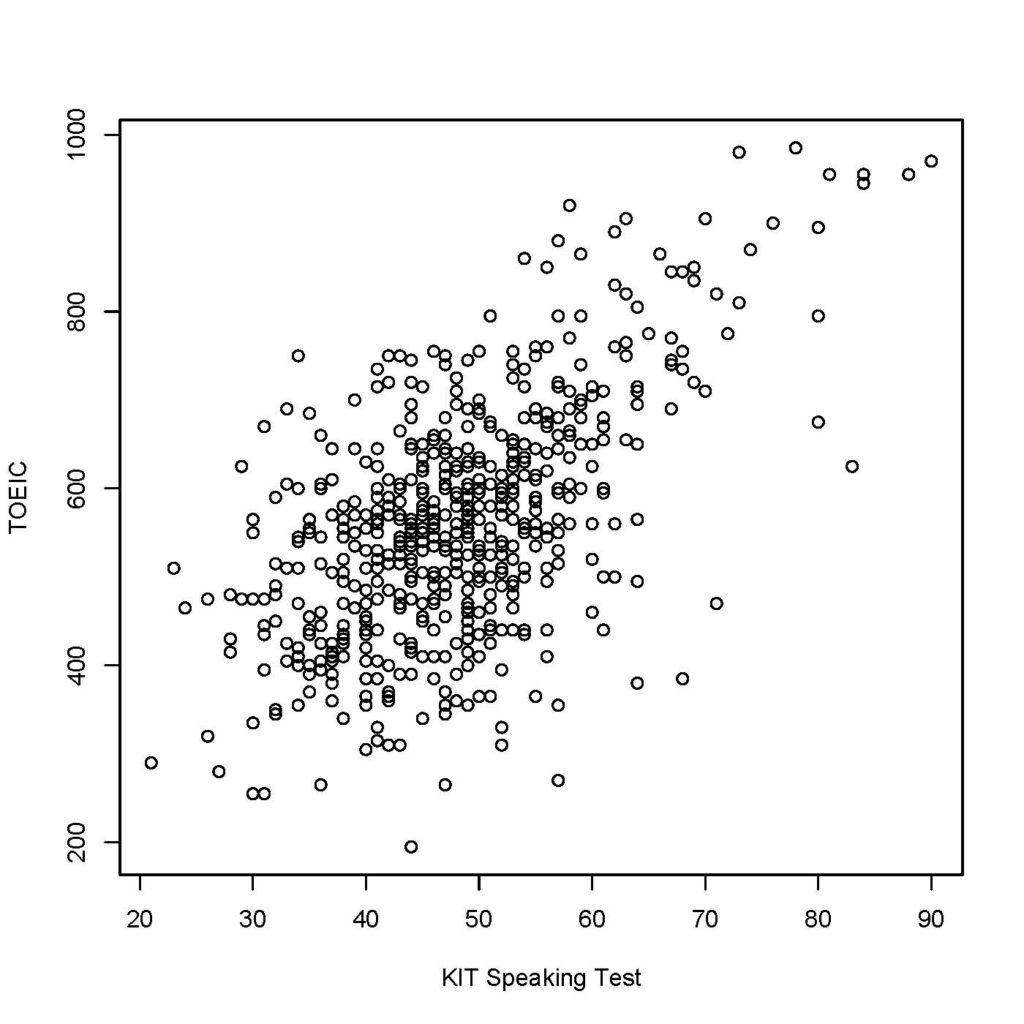
The figure below plots KIT Speaking Test scores on the horizontal axis and TOEIC scores on the vertical axis. The correlation coefficient between the two is 0.59.
4.2 Corpus size
This corpus contains data of 574 examinees, ● hours, and ● words. The table below shows a breakdown of each version’s data.
| No. of examinees | No. of words | Total response time | |
|---|---|---|---|
| Ver. 1 | |||
| Ver. 2 | |||
| Ver. 3 | |||
| Total | 574 |
4.3 Corpus files
The following three corpora (all in .txt format) are available for download.
(1) Video Indexer version
The speech responses are transcribed using Video Indexer (currently Video Analyzer for Media), an automated transcription tool by Microsoft. Note that the performance of Video Indexer is as of 2019–21, when the work was done.
(2) Untagged version
(1) is modified manually.
(3) Tagged version
(2) is tagged manually.
The file is divided into a header section and a transcribed speech response section. The file format and transcription/tagging methods conform to the NICT JLE Corpus as much as possible. Please refer to the transcription/tagging manual in 5.3 for detailed transcription/tagging rules.
4.3.1 Header information
The following header information is attached to the text files (1) through (3). This allows us to analyze the relationship between the header information and the utterance.
| Header information | Meaning |
|---|---|
| <grade> | University grade |
| <nationality> | Nationality |
| <sex> | Sex (1 for male, 2 for female) |
| <version> | Version of the speaking test |
| <total_score> | Score in the speaking test (0–100) |
| <ta_rank> | Task Achievement rank in the speaking test (0–5) |
| <td_rank> | Task Delivery rank in the speaking test (0–5) |
| <toeic_score> | TOEIC score(10–990) |
| <toeic_rscore> | Score of Reading Section in TOEIC(5–495) |
| <toeic_lscore> | Score of Listening Section in TOEIC(5–495) |
| <experience1> | The following are the responses to the survey by TOEIC. How many years have you studied English? A=4 years or fewer/B=4–6 years/C=6–10 years/D=10 years or more/Blank=No answer |
| <experience2> | Which of the following language skill(s) is/are the most important for you? A=Listening/B=Reading/C=Speaking/D=Writing/E= Listening and Speaking/F= Reading and Writing /G=All of them/Blank=No answer |
| <experience3> | What percentage do you use English in your daily life? A=0%/B=1–10%/C=11~20%/D=21~50%/E=51~100%/Blank=No answer |
| <experience4> | Which of the following language skills do you use the most? A=Listening/B=Reading/C=Speaking/D=Writing/E= Listening and Speaking/F= Reading and Writing/G=All of them/Blank=No answer |
| <experience5> | How often does your lack of English proficiency prevent your communication? A=hardly ever/B=occasionally/C=sometimes/D=often/E=usually/ Blank=No answer |
| <experience6> | Have you ever stayed in a country where English is the primary language? A=No/B=6 months or fewer/C=6~12 months /D=1–2 years/E=1 or more years/Blank=No answer |
| <experience7> | What was the purpose of your stay in a country where English is the primary language? A=Study (excluding learning English)/B=To participate in an English language learning program/C=Travel (excluding business)/D=Business/E=Others/Blank=No answer |
4.3.2 Tags
The following tags are assigned to file (3) to describe the characteristics of the speech responses.
| Tags | Meaning |
|---|---|
| <F> </F> | Filler |
| <R> </R> | Repetition |
| <R?> </R?> | Repetition (not confident in listening) |
| <SC> </SC> | Self-correction |
| <SC?> </SC?> | Self-correction (not confident in listening) |
| <TO> </TO> | Timeout |
| <RE> </RE> | Recording error |
| <nvs> </nvs> | Non-verbal sound |
| <CO> </CO> | Cutoff (suspended speech) |
| <?> </?> | Not confident in listening |
| <??> </??> | Completely inaudible |
| <H pn=“X”> </H> | Proper nouns, discriminatory terms, etc. |
| <JP> </JP> | Japanese |
| <.> </.> | Pause (2–3 sec.) |
| <..> </..> | Pause (3 or more sec.) |
| <laughter> </laughter> | Laughing while speaking |
5. Downloads
5.1 Corpus files
Each corpus file is downloaded in zip format. A password is required to open the file. It can be obtained by filling out the registration form.
- Video Indexer version: Ver. 1 (XXXXX updated)
- Untagged version: Ver. 1 (XXXXX updated)
- Tagged version: Ver. 1 (XXXXX updated)
※The file ‘316’ was removed from the corpus because it was silent.
5.2 Test items
- Ver. 1 (XXXXX updated)
- Ver. 2 (XXXXX updated)
- Ver. 3 (XXXXX updated)
※Although scripts of the conversations are included in Part 2, the scripts are not shown in the actual test. The examinees only listen to the conversation audio.
5.3 Transcription/tagging manual
- Ver. 1 (2022.04.20 updated)
6. Using the corpus on Jupyter Notebook
The corpus is also available on Jupyter Notebook.
7. Our team
Researchers
- Katsunori Kanzawa (Kyoto Institute of Technology)
- Yuichiro Kobayashi (Nihon University)
- Jaeho Lee (Waseda University)
- Haruhiko Mitsunaga (Nagoya University)
- Masayuki Mori (Kyoto Institute of Technology)
- Yusuke Tanaka (Fukuoka University)
Transcribers (Graduate students)
- Taishi Chika (Kyoto University), 2019–2020
- Mitsuyuki Kato (Kyoto Prefectural University), 2019
- Takumi Kitahara (Kyoto University), 2019–2020
- Satoshi Taniwaki(Ritsumeikan University),2019
- Taku Motozawa (Kyoto University), 2020
※Affiliations are as of the time of the work.
8. Grants
This project has been supported by the following grants:
- JSPS KAKENHI No.19K00849 “Corpus development based on speech responses by Japanese university students to the computer-based English speaking test” (AY 2019–2021)
- JSPS KAKENHI No.22K00736 “Exploring Task Achievement for improving scoring efficiency in English speaking tests” (AY 2022–2024)
9. Terms and conditions
By downloading the KIT Speaking Test Corpus or using it on Jupyter Notebook you are agreeing to the following terms and conditions. If we find any violation, we will issue a warning. If you fail to comply with the warning promptly, we will take legal action. Please note that these terms and conditions may be updated without notice and the latest version will be applicable.
- Mention the name of the corpus (“KIT Speaking Test Corpus”), when you publish a research using it.
- Use the corpus at your own risk. The development team is not responsible for any damage, loss, or other disadvantage that may result from the use of the corpus.
- In principle, original speech responses to the KIT Speaking Test are used for this corpus without alteration. The development team shall not be responsible for the content of the utterances, which might contain inappropriate material.
- Despite the best efforts of the development team in building the corpus, the corpus may contain errors. The development team assumes no responsibility for them. If you find any error, please contact the project leader, Katsunori Kanzawa at kanzawa[at mark]kit.ac.jp.
- The corpus and website may be updated or deleted without notice.
- Modification and/or redistribution of the corpus is prohibited.